 | | Привет! Это проект Digital Garden: мы строим медиа и платформу о практике исследования в новой реальности. | |
| | Внутри этого письма, как всегда, классные статьи и ссылки, заинтересовавшие нашу команду, а еще лонгрид: интервью с лингвистом, PhD-кандидатом Артемом Новожиловым о том, как большие языковые модели используются для изучения нашего мозга. Enjoy! | |
| | | Anthropic Economic Index: Tracking AI’s role in the US and global economyИсследователи из Anthropic проанализировали, как доступ к ИИ и особенности его использования различаются между странами с разным уровнем экономического развития. Из очевидного: чем богаче страна, тем вероятнее, что у большего числа её граждан есть доступ к нейросетям. Из интересного: выяснилось, что в странах с более низким ВВП Claude в основном применяется для автоматизации рутинных задач. В более развитых экономиках нейросети чаще используются в сфере науки, образования и креативных индустрий. Ученые предупреждают, что в будущем такое положение дел может привести к усилению глобального экономического разрыва как между странами, так и внутри отдельных обществ. | | | | *только с уважением к научным методам!Why science needs outsiders?Исследователи Alvin Djajadikerta и Laura Lungu в эссе для Work in Progress рассуждают о роли «чужаков» в научных открытиях. Они напоминают, что нередко научные революции происходили под влиянием идей аутсайдеров — людей из смежных областей знания, случайных самоучек вне академии или вовсе не ученых. Без такого притока взглядов производство научного знания рискует превратиться в бюрократическую доработку старых теорий и потерять связь с реальным миром. | | | | Bullshit Jobs Will Save Us AllБредовую работу вообще-то принято ругать. Однако предприниматель и автор Tim Leberecht предлагает взглянуть на нее иначе. По его мнению, даже если такая работа не имеет глобального значения, это не означает, что она лишена социального смысла. В мире, где ИИ готов забрать у нас все мелкие задачи, именно рутинная «бессмысленность» — бесконечные таблицы, одинаковые презентации и формальные созвоны — может стать опорой, источником минимального чувства признания, столь необходимого человеку сегодня. | | | | AI-designed viruses are here and already killing bacteria Ученые из Стэнфорда и Arc Institute впервые создали вирусы с геномами, полностью сгенерированными ИИ. Модель Evo, обученная на миллионах бактериофагов, предложила сотни новых вариантов ДНК, из которых 16 оказались жизнеспособными: они смогли заразить бактерии кишечной палочки и уничтожить их. Ресерч открывает новые пути для лечения бактериальных инфекций и ускоряет исследования в синтетической биологии. И да, ученые предупредили, что эта модель теоретически может быть использована для создания более опасных вирусов, если попадет в неправильные руки. | | | | Public trust in science has declined since COVIDГруппа ученых-вирусологов из США, Франции и ЮАР в статье для Nature пишут о серьезном системном кризисе, с которым столкнулась их область. После пандемии COVID-19 доверие к вирусологии резко снизилось. Постоянные споры о безопасности исследований заставляют ученых делать свою работу максимально публичной. Однако нередко это приводит к обратному эффекту: исследователи становятся более закрытыми и осторожными, опасаясь критики, давления или политизации своих проектов. В результате прозрачность обсуждений внутри научного сообщества падает еще сильнее, затрудняется обмен знаниями и оценка рисков, а снаружи усиливаются слухи, теории заговора и недоверие. | | |
| | | | Рассказываем о самых важных исследованиях сентября: ИИ, который меняет сценарий проектирования лекарств, глубокий социальный смысл онлайн-образования и рекордный показатель ощущения личной безопасности на фоне глобальной нестабильности. | | |
| | LLM в психолингвистике: что искусственный интеллект может рассказать о нашем мозге | |
| Помогут ли большие языковые модели объяснить, как язык формируется, хранится и функционирует в системе мышления?Артем Новожилов, PhD-кандидат Университета Нова-Горица, Словения, рассказывает, почему LLM стали удобным зеркалом для психолингвистики, и какие выводы о работе мозга уже удалось сделать – в новом интервью для Digital Garden. | |
| | G: Артем, а расскажи простым языком: чем занимается психолингвистика?
А: Это дисциплина на стыке психологии, лингвистики и нейронауки. Мы изучаем, как «живёт» язык в голове: как обрабатывается и воспринимается речь, как структура языка усваивается на всех трех уровнях сознания: вычислительном (что и зачем делает эта система?), алгоритмическо-представленческом (как именно задачи системы реализуются?) и имплементационном (как это происходит физически) в сознании.
Как и любая наука, лингвистика делится на фундаментальную и прикладную. Первая разбирается, какими вообще бывают языки, и какие когнитивные ограничения (например, объём рабочей памяти) формируют грамматику, а какие черты языка диктует сама логика информационных процессов.
В прикладном секторе выделяют три крупных маршрута. Корпусная лингвистика строит и размечает гигантские базы текстов, решая, какие теги и алгоритмы нужны, чтобы другие исследователи могли «кормить» модели чистыми данными. Клиническая лингвистика изучает, как нейроотличный мозг обрабатывает речь и что делать, когда система дает сбой, например, при инсульте, дислексии и аутизме. Вместе все эти направления не только помогают разрабатывать новые виды терапии, но и объясняют, как устроен язык. А компьютерная лингвистика отвечает за все, что связано с автоматическим переводом, расшифровкой речи и созданием саммари.
Психо- и нейролингвистика занимают особое место между этими полюсами: они соединяют теоретические модели из фундаментальной лингвистики с экспериментальными и технологическими методами прикладной. По сути, это мост между теориями о том, как устроен язык, и эмпирическими способами понять, как именно он живёт в мозге. | |
| | G: То есть психолингвистика — это не только о языке и тексте?
А: Да, нейро- и психолингвистика изучают, что происходит в мозге, когда система речи работает штатно — и когда дает сбой. После инсульта, например, может возникнуть афазия — трудности с пониманием или порождением слов, и ученые составляют тесты, чтобы подобрать точную реабилитацию.
При расстройстве аутистического спектра страдает понимание прагматики: влияния контекста, социальной ситуации, отношений между собеседниками, времени места общения на выбор языковых средств.
А у людей с дислексией мозг ошибается на этапе распознавания букв: это замеряется в том числе при помощи айтрекинга – регистрации движения глаз. Камера фиксирует сотни микропауз взгляда у людей с дислексией там, где обычный читатель делает четыре-пять. Получив такие данные, лингвисты изучают, помогут ли определенные шрифты читать быстрее. Таким образом, изучая речевые процессы, психолингвистика переводит знания о мозге в практические инструменты, которые возвращают людям способность свободно общаться.
| |
| | G: Ты недавно съездил на несколько конференций: Human Sentence Processing, Formal Approaches to Slavic Linguistics и Annual Meeting of the Cognitive Science Society в США, Architectures and Mechanisms for Language Processing в Праге, и даже на SyntaxFest 2025 в Любляне. Расскажи о том, что происходит в психолингвистике прямо сейчас?
А: Главная новость — в игру вошли большие языковые модели (LLM) — те же GPT, только под капотом у исследователей. LLM ускоряют аналитические и вычислительные задачи: мы автоматизируем разметку корпусов, вычисляем сложные синтаксические параметры, автоматизируем создание тестов. Но именно в психолингвистике LLM становятся очень удобным «зеркалом» для науки: у модели нет врожденного чувства языка, поэтому сравнивая её поведение с человеческим, мы видим, где работают законы передачи информации, а где вступают в дело особенности мозга. | |
| Krieger, B., Brouwer, H., Aurnhammer, C., & Crocker, M. W. (2025). On the limits of LLM surprisal as a functional explanation of the N400 and P600. Brain Research, 1865, 149841. https://doi.org/10.1016/j.brainres.2025.149841 Huber, E., Sauppe, S., Isasi-Isasmendi, A., Bornkessel-Schlesewsky, I., Merlo, P., & Bickel, B. (2024). Surprisal From Language Models Can Predict ERPs in Processing Predicate-Argument Structures Only if Enriched by an Agent Preference Principle. Neurobiology of Language, 5(1), 167–200. https://doi.org/10.1162/nol_a_00121 | |
| | G: Класс, это как-то экспериментально подтверждается?
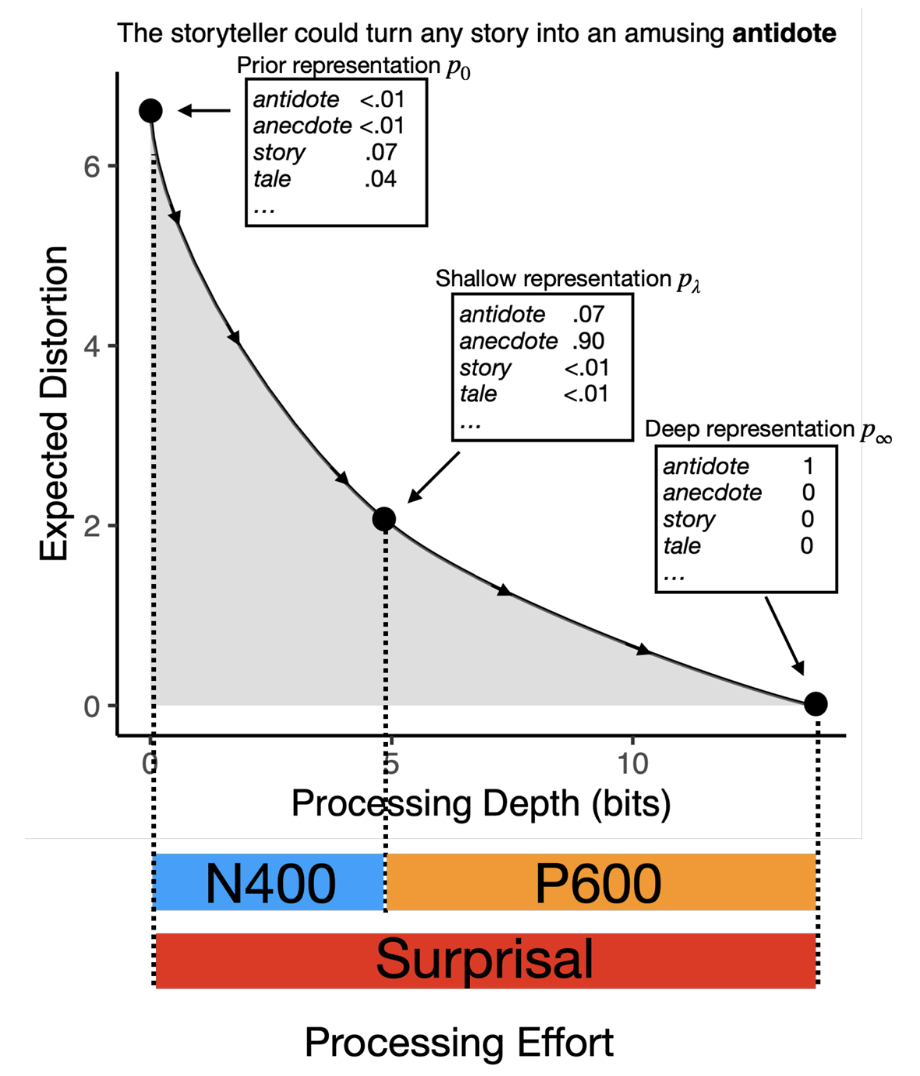
А: Да, конечно. Например, исследователи берут короткие тексты и показывают их людям слово за словом, одновременно «скармливая» тот же материал большой языковой модели. У модели сразу подсчитывается Surprisal — число, которое говорит, насколько данное слово для неё неожиданно. Обыденные слова дают низкий surprisal, редкие или странные — высокий. У человека неожиданность фиксируется датчиками ЭЭГ, а также увеличением пауз, времени чтения и фиксации взгляда на слове. Если предложение «сломано», на графике электрической активности мозга вспыхивают два характерных пика: N400 и P600. N400 появляется через ≈ 0,4 секунды, когда слово нарушает грамматику («Он намазали на хлеб варенье»); P600 — ещё на две десятых позже, если слово грамматически подходит, но абсурдно по смыслу («Я намазал на хлеб носки»).
Результаты любопытны. Surprisal модели хорошо совпадает с N400: когда алгоритм и мозг видят грамматический сбой, оба «спотыкаются» одновременно. Реакция, аналогичная P600, у модели тоже присутствует — просто не как отдельный сигнал, а как стоимость пересборки предсказания (разница между Surprisal на последнем и предпоследнем слове, или KL-divergence). Это позволяет точнее связать вычислительный и нейрофизиологический уровни описания языковой обработки.
| |
|  | | Decomposition of surprisal: Unified computational model of ERP components in language processing | | Jiaxuan Li and Richard Futrell. Department of Language Science, University of California Irvine | | | |
| | Вторая линия исследований — использование больших языковых моделей как «тест-полигона» для проверки пределов человеческого мышления. Здесь учёные намеренно ставят модели и людей в одинаковые условия и ищут расхождения. Например, модели можно искусственно разрешить «удерживать» не больше двух фраз одновременно; когда это ограничение вводят, её прогнозы времени чтения и вероятность ошибок становятся похожими на человеческие данные, что подтверждает гипотезу о малом количестве параллельно рассматриваемых предсказаний человеком. Похожим образом проверяют так называемый порог неразличения частотности: люди почти не замечают разницу между очень редкими словами, тогда как модель различает их без труда. Если задать модели упрощённый «порог», численные результаты вновь приближаются к поведению читателей. | |
| Hahn, M., Futrell, R., Levy, R., & Gibson, E. (2022). A resource-rational model of human processing of recursive linguistic structure. Proceedings of the National Academy of Sciences, 119(43), e2122602119. https://doi.org/10.1073/pnas.2122602119Andrea de Varda, A., & Marelli, M. (2024). Locally Biased Transformers Better Align with Human Reading Times. In T. Kuribayashi, G. Rambelli, E. Takmaz, P. Wicke, & Y. Oseki (Eds.), Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics (pp. 30–36). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.cmcl-1.3 Kuribayashi, T., Oseki, Y., Brassard, A., & Inui, K. (2022). Context limitations make neural language models more human-like. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. EMNLP 2022. https://doi.org/10.18653/v1/2022.emnlp-main.712 | |
| | Третья линия исследований — поиск универсальных «языковых правил-по-умолчанию», или баясов. Лингвисты давно замечают, что во всех языках мира встречаются одни и те же запреты: например, нельзя выносить часть сложного вопроса слишком далеко от глагола (так называемые «синтаксические острова»).
Также мы изучаем порядок слов: например, языки, в которых основным порядком слов является дополнение – глагол – подлежащее (OVS), почти не встречаются; по всему миру известно всего одиннадцать таких языков, а с порядком OSV – всего четыре.
Раньше считали, что это врожденные особенности человеческого мозга. Теперь учёные запускают большие языковые модели и обнаруживают: без всяких врождённых настроек модели редко используют эти конструкции. Это подталкивает к мысли, что ограничения могут возникать из самой логики передачи информации — короткие, легко предсказуемые фразы передаются надёжнее, а значит и в языке закрепляются.
Чтобы проверить эту гипотезу, сравнивают модели разного размера и устройства. Небольшие двунаправленные сети (читают предложение сразу слева и справа) иногда предсказывают поведение читателя лучше, чем огромные однонаправленные GPT-модели, что показывает: не всё решает масштаб, важна архитектура и то, как модель видит контекст. Исследователи также учитывают технические детали, вроде того, на какие «кусочки-токены» модель режет слова: это влияет на способность ловить редкие формы и может создавать свои искусственные «баясы».
В итоге, сопоставляя поведение разных LLM с реальными языками, ученые отделяют ограничения, продиктованные человеческим восприятием, от тех, что задаются чистой информационной экономией, и тем самым уточняют теорию, почему язык устроен именно так. | |
| | Abramski, K., Improta, R., Rossetti, G., & Stella, M. (2025). The “llm world of words” english free association norms generated by large language models. Scientific data, 12(1), 1–9.
Abramski, K., Lavorati, C., Rossetti, G., & Stella, M. (2024). Llm-generated word association norms. In HHAI 2024: Hybrid Human AI Systems for the Social Good (pp. 3–12). IOS Press. | |
| | G: Можно ли сказать, что LLM, в первую очередь, помогают нам понять, как устроен наш мозг?
А: Да, большие языковые модели действительно стали новым окном в работу человеческого мозга. Когда мы сравниваем их статистические прогнозы со всплесками ЭЭГ, движениями глаз или скоростью чтения, мы получаем (относительно) простую, численно измеримую «модель» тех же процессов, которые раньше приходилось изучать долгими поведенческими тестами.
При этом модели ничем «врожденным» не обладают: они учатся только на тексте. Именно поэтому совпадения с данными мозга показывают, какие ограничения диктует чистая информатика языка, а расхождения — где вступают в дело особенности нашей памяти, внимания или телесного опыта. В итоге языковая модель становится универсальным тест-полигоном, где можно не только безопасно «пощупать» границы человеческого мышления, но и проверять гипотезы о возможных и невозможных для человека языках — и шаг за шагом сделать их понятнее как нам самим, так и машинам, которые мы создаём.
| |
| | G: И напоследок – расскажи нам о своих последних работах?
А: За последнее время у меня вышло две новые статьи, и еще две ждут публикации. Мы изучаем, как носители русского и сербскохорватского языков оценивают приемлемость (естественность или правильность) предложений.
Для этого мы используем специальные метрики, которые помогают описывать и предсказывать такие оценки. Например, средняя дистанция зависимости (Mean Dependency Distance) показывает, насколько далеко в предложении стоят слова, которые должны быть связаны друг с другом. Чем больше расстояние, тем труднее мозгу обработать такую фразу — и тем менее естественно она звучит. Другая метрика, проективность (Projectivity) проверяет, пересекаются ли связи между словами.
Если пересекаются, структура считается более сложной, и предложения обычно оцениваются хуже. Эти знания помогают нам в создании вычислительно точных, когнитивно обоснованных моделей приемлемости для языков со свободным порядком слов, а также позволяют отделить жесткие грамматические ограничения от ограничений обработки (когнитивной нагрузки). | |
| | | | Вы получили это письмо, потому что подписались на рассылку Digital Garden. Спасибо, что вы с нами. | Вы можете отписаться от нас в любой момент здесь. Мы будем по вам скучать. | | | |
| |




